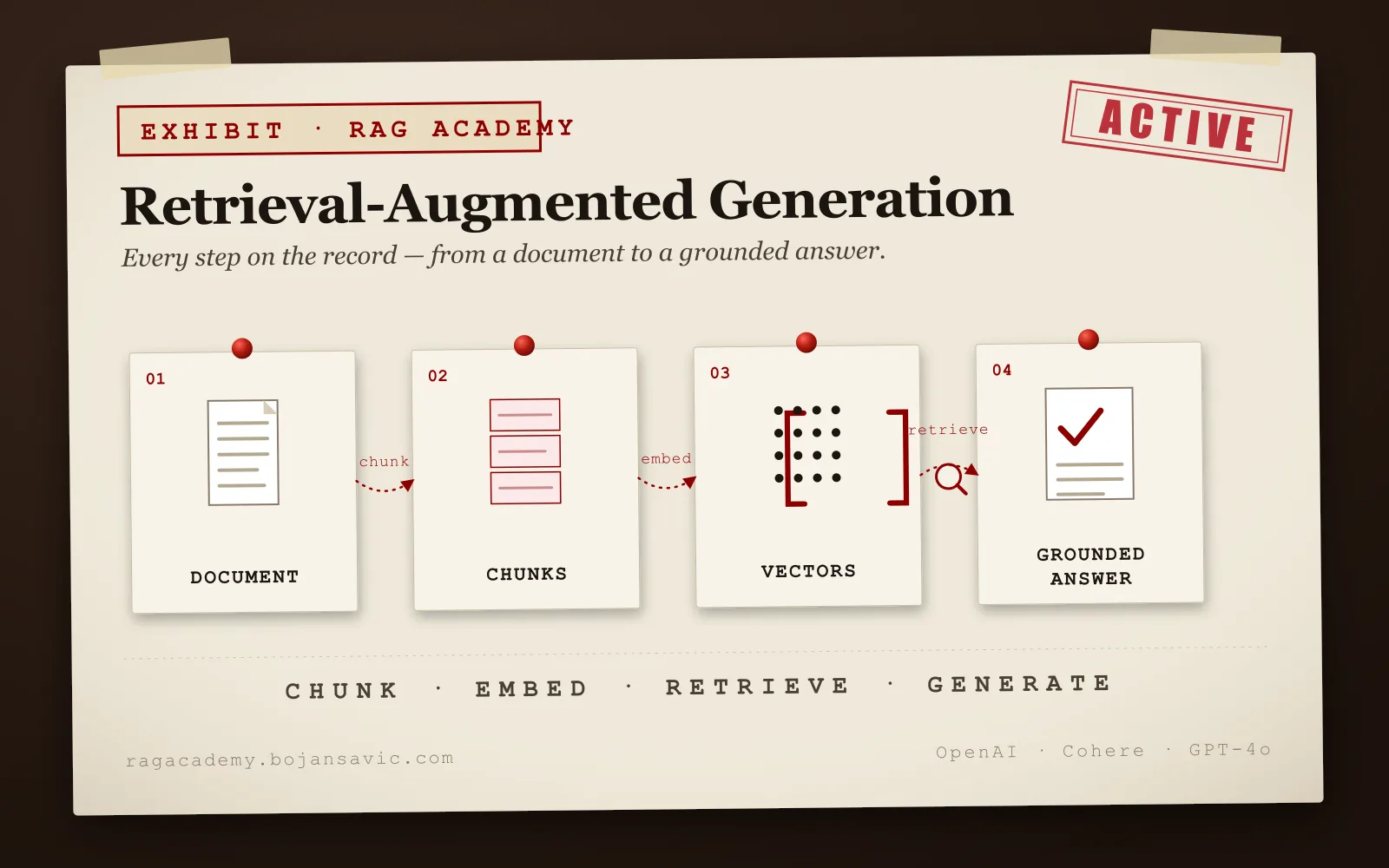
A web app that exposes every stage of a RAG pipeline — chunk → embed → retrieve → generate — so you can see the choices that most RAG tutorials hide behind a chatbot.
Live at ragacademy.bojansavic.com — self-hosted and free to try. Sign up, run the pipeline on your own text, and watch every step. It calls real OpenAI + Cohere + GPT-4o APIs, so a light per-visitor daily cap keeps the bill honest.
What it does
Step through a full RAG loop on your own document (upload, paste, or use a bundled sample):
- Chunk. Try four strategies side-by-side: fixed-size with configurable word count + overlap, sentence-boundary, recursive character splitter (the one that actually preserves ideas — uses punctuation, paragraph structure, and grammar to keep meaning intact), or a custom split by symbol/word with author-defined overlap. The chunk count and shape updates live as you tune.
- Embed. Generate vectors for every chunk with OpenAI and Cohere in the same pass — ~1500d vs ~1000d — then inspect the similarity matrix between any two chunks, per model. Same chunk, different nearest neighbours, because the two models encode meaning differently.
- Query. Ask a question in plain language; watch it get vectorised and searched against the chunk index. Results are shown per embedding model so the divergence is legible — the same query can pick chunk 3 from OpenAI and chunk 4 from Cohere, and the tool shows you why.
- Generate. The top chunks plus the original question go to GPT-4o; the grounded answer renders next to the retrieved context so you can check the answer against its source, not just trust it.
Every step has an inline explainer so the mechanism stays visible. Nothing in the pipeline is magic — just a chain of deterministic choices you can inspect.
Why it exists
Most RAG tutorials treat the pipeline as a black box: drop a PDF in, get a chatbot out. That’s fine for shipping a demo and useless for understanding why a RAG system fails or succeeds. The failures sit upstream of the LLM call — wrong chunk size, wrong overlap, wrong embedding model, wrong top-k — and you can’t debug what you can’t see.
RAG Academy is the tool I wished existed while learning this stack. Every choice at every stage is visible, swappable, and comparable. Pick a chunking strategy, watch the chunks change. Swap the embedding model, watch the similarity rankings change. Ask a question, watch retrieval pick a different chunk, watch the answer drift.
The L&D angle is why the visual design matters — you teach what you can see. The AI-for-L&D practitioner angle is why this matters in practice: the teams buying “AI-powered learning” rarely understand what their system is actually retrieving, and the pre-processing step — the one that decides most of the quality — is the one they’re least equipped to reason about.
Tech
- Host — self-hosted at ragacademy.bojansavic.com (React + Express + Postgres, in Docker behind Traefik on my own VPS)
- Embeddings — OpenAI (~1536d) + Cohere (~1024d), run side-by-side for every document
- Retrieval — in-memory vector store, cosine similarity, top-k ranked per embedding model
- Generation — GPT-4o for the final grounded answer
- UX — step-by-step flow with inline explainers at every concept boundary (chunk, vector, similarity, retrieval, augmentation, generation)
Status
Live and open at ragacademy.bojansavic.com — sign up and run the full loop on your own text. Because every run spends real API credits, there is a light per-visitor daily cap. Follow-up deep-dives planned on how chunking strategy alone changes answer quality.